|
|
Information Letter 7 was a general status report. It summarised an eventful month: development got underway on AutoCAD on both the 8086 host machines (in C), and on the Z-80 (using PL/I). We had given up on the old source code, and were furiously rewriting it in the new languages. It included the initial documentation of Auto Book, “the product that would not die”.
This information letter is being mailed with the minutes of the July general meeting appended to the end. Other items are included about things not brought up at the meeting.
A month ago I had the feeling that the company was spinning its wheels and getting nowhere. Now I think that most of the problems we had getting under weigh were normal start-up problems, which are being resolved. Definite progress is being made on all of our major products, and we can see a clear path to completion on most of them.
We're still collecting the tools, hardware and software, that people need to get the work done. If you're still waiting, be assured that you will not wait forever (or even better, help us out in getting what you need). I'll try to summarise the major project status below.
We've established a more formal structure for the monthly meetings, patterned after the original Working Paper suggestions. This form (described in the attached minutes) will minimise the “endless miasma syndrome”, and allow the gist of the meeting to be condensed onto paper for those who cannot attend. Furthermore, we hope that the new format will let everybody know exactly where every project stands and what everybody is doing. At the end of each meeting, everybody should know exactly what they should be doing, and how it connects to all other work in progress.
As originally suggested, after the formal meeting we can have technical sessions on the various projects.
Kern Sibbald has completed conversion of the cleaned-up original Autodesk to CB80 under CP/M. He has prepared an internal release disc of this test version to get comments on the user facilities it offers. Each person who has CP/M capability should have already received this disc. Kern is now defining the master database that will underlie the completed system, and implementing a mockup of the database so he can convert the program to use the new database routines.
In the process of converting Autodesk to CB80, Kern segmented the program into initialisation, screen, and command overlays. This reduced the maximum size of the program to a little over 38K, so we now have a comfortable amount of space in which to work, as opposed to the 9900 version which was teetering on the brink of memory insolvency.
As soon as a real appointment calendar is installed, we will have a CP/M demo version we can begin to show to potential distributors.
Implementation of QBASIC on the 8086 is progressing rapidly. Hal Royaltey and David Kalish have designed the memory model and parameter passing conventions for the object code. Hal has converted the floating point library, and is filling in the rest of the support routines prior to bulk converting the runtime library. All tools needed for this effort are in hand.
Dan Drake has made a complete audit of the differences between QBASIC and CB80 and has prepared a 10 page summary of differences and tasks required in META, QBASIC pass 1, QP2, and the runtime library to resolve the differences. He is planning to do the conversion of the compiler.
John Walker has ported META to the 8086. The port used the new C
compiler we bought.![]() META was changed to generate C instead of
assembly language code, and the META library was rewritten in C.
As a result, META is now instantly portable to any machine which
has C.
META was changed to generate C instead of
assembly language code, and the META library was rewritten in C.
As a result, META is now instantly portable to any machine which
has C.![]() We may very well use C to write the second pass of QBASIC
(QP2) as well (it's currently in QBASIC). If we do it all in C,
the port to the 68000 will be a piece of cake as far as the
compiler is concerned (since all the 68000's announced seem to
have C).
We may very well use C to write the second pass of QBASIC
(QP2) as well (it's currently in QBASIC). If we do it all in C,
the port to the 68000 will be a piece of cake as far as the
compiler is concerned (since all the 68000's announced seem to
have C).
The code structure which has been defined will be the first known totally general 8086 compiler implementation. There will be no limit at all on the size of a program. This should make our compiler very attractive compared to all the others that stick you with 64K data and 64K code total.
A major change of direction in the MicroCAD project should result
in completion of the conversion within the next month. Since we
were able to find an excellent C compiler for the 8086, under both
PCDOS/MSDOS and CP/M-86, we've decided to convert the SPL code to
C rather than port SPL. Keith Marcelius surveyed the available C
compilers and decided that the Computer Innovations compiler was
the clear choice. We bought two copies of the compiler, and Greg
Lutz and John Walker beat on it enough to satisfy themselves that
the compiler was sound. John Walker used it to port META as noted
above, and converted a set of high-precision mathematical
functions to C (the Computer Innovations compiler has full IEEE
single and double precision floating point, but having no math
functions in the library is delivered free of SIN).![]()
The C is weak in floating point I/O, but since the compiler is supplied with complete source code for the library, and since all the relevant routines are written in C, this is easily remedied. We have found Computer Innovations to be very helpful and easy to work with, and it seems to be an outfit operating in a style very much like our own.
Greg Lutz and Dan Drake will be converting the SPL code to C. We've purchased a Houston Instruments HI-PAD digitiser which we will hook up to both the Victor and the IBM PC to test MicroCAD. We're currently looking at plotters, and are trying to see if we can work some kind of cooperative marketing deal with Houston Instruments if we use their plotters as well as their digitisers.
Our current plan for MicroCAD is to have a root segment which contains all the device-dependent parts. That segment will load the “guts” of the package which will be totally machine-independent. This has the advantage of modularising the package, making it easier to field-configure, and getting the potentially large drivers out of the address space of the package itself (it takes 40000 bytes to hold the screen bit map on the Victor).
John Walker has undertaken the task of trying to shoehorn MicroCAD
onto the 8080. The effort seems worthwhile investigating as the
potential market a success would open up is enormous. The effort
was initiated as the result of the question “Have you ever
encountered a program you couldn't make fit on any
machine?”.![]()
Mike Ford has been testing Window on his CP/M system and has found a couple of bugs which will be corrected. Duff Kurland and Mauri Laitinen have been converting the line database to 8080 code. The memory-only version is complete and currently being tested. After that's checked out, the disc stuff will be installed and we will have a product ready to go out the door (pending documentation upgrading).
For those of you who haven't used Window on CP/M, I'll mention that we've installed a completely new terminal configuration mechanism which completely eliminates the need to compile terminal drivers and link them with WINDOW. The terminal is totally described by a master terminal definition file. We plan to supply a menu-driven program which generates and updates these terminal descriptions.
As mentioned in the minutes of the meeting, we've requested everybody to funnel in a list of tasks before each meeting so that we can print them in the minutes and let everybody know what the others are accomplishing. The process of getting these tasks in and concentrated worked so poorly this time that I don't think it makes sense trying to summarise them here—it would likely create more confusion than it would dispel. Please keep this in mind in the future—each monthly letter from now on should contain detailed task lists. I'd like to work out a way (maybe via MJK) that I can prepare the task summaries without having to retype pages of information.
Most people in the company are now using the MJK teleconference system to interchange messages. As requested, I've added the conference system user names to the “Names and Addresses” directory at the end of this letter (after the phone numbers).
The conference system has been afflicted by the recent times of tribulation in TYMNET. TYMNET has been installing new software, and we've been through yoyo reliability, double spaced input lines, character delete that comes and goes, etc. All we can do is put up with it. The problems are in TYMNET, not the conference system.
Please note that charges for the conference system, including TYMNET connect time (the largest component of the cost), drop by more than 50% in non-prime time, that is, 18:00 to 07:00 Pacific local time (the time that's displayed when you log on). The reduced charges also apply on Saturdays, Sundays, and holidays all day. Please help us save money by using the system when it's cheap. Note also that MJK's preventive maintenance remains from 17:00-17:30 Pacific time, so if you try to log on at that time you'll get “Can't initiate new sessions now”.
To further reduce charges on the system, I've reversed a change made to the system some time back and made the system store messages for people in files keyed with their names. This means you can check whether there are any messages for you without calling the CONFRX program and incurring the charges to load and execute it. At the point you're about to type RUN CONFRX, type LISTF instead. You'll see a file directory listing. If you see a file with your user name preceded by “MF”, then you have messages. If there's no such file, and you don't want to send any messages, you can type BYE immediately and log off. Thus, if you user name were GONZO, you would look for a file “MFGONZO” in the file directory.
The Subchapter S alternative we considered before turned out not to be possible after all, because one of the stockholders (MSL) was a corporation, not a person. This disqualifies AI from Subchapter S. As a result, we'll go ahead soon with the option plan to bring in the rest of the people. We should have done this already, but the press of work kept us from getting to it.
C is shaping up to be an important language in AI's plans. It looks like the language of choice for the 8086 based on the Computer Innovations compiler, and of course it is the workhorse on any of the Unix ports to the 68000 or elsewhere.
If you don't know C, it would be a good idea to pick up a book and start reading up on it. The reference is The C Programming Language by Brian Kernighan and Dennis Ritchie, Prentice-Hall, 1978 ISBN 978-0-13-110362-7. AI will reimburse the cost of your buying this book.
The Computer Innovations C is a full, unrestricted, implementation of the language as described in the book. If anybody knows of a similar 8080 C with good code and an attractive runtime licensing deal, please let me know.
I'm currently exploring the option of converting WINDOW to C for
the 8086.![]()
Utterly out of the blue, Marinchip has completed the most spectacular sales month in its history. In June we sold more than our total sales for 1978 and 1979 combined. If sales were to continue at the present pace, Marinchip would be shipping at an annualised rate of $850,000 (neglecting for the moment the little detail that John Walker would disintegrate in the process). This is being mentioned because if you've been waiting for John Walker to do something for you, you'll probably have to wait a bit longer. As a result, we've tried to further decentralise the communications in AI—a lot of information was passed through John Walker simply because that was easy. But it won't work at the moment. We expect the June results to be a one-time blip since most of the sales were unexpected one-shot sales rather than dealer or OEM business. However, July looks like a barnburner as well.
John Walker has been playing around with a new product idea called Auto Book. A M9900/QBASIC test program has been developed to explore ideas. If the product looks worthwhile, we can consider it as an innovative way to distribute manuals for our products, to offer an impressive help facility, and as a product in its own right. I'm including the working paper on the product with this mailing for your review and comments. Richard Handyside and Jodi Lehman have copies of the program and are currently evaluating it and making suggestions.
On the 7th and 8th of August there will be an Autodesk/Marinchip
dealers meeting in London. Rudolf Künzli, Richard Handyside, and
Peter Goldmann will be there. If you have items that would make
sense to bring up at the meeting, please try to get them to the
people involved before the meeting.![]()
During this period, monthly weekend get-togethers comprised almost all of the face-to-face contact between the people involved in the company. Dan Drake's minutes of the July, 1982 meeting were mailed with Information Letter 7.
The July general meeting was held on Saturday, June 26, 1982, at Jack Stuppin's house. (For those who missed it or have forgotten, the algorithm for computing meeting dates is at the end of the minutes.)
The meeting was called to order at 1:10. Present were Dan Drake, Mike Ford, Dave Kalish, Greg Lutz, Keith Marcelius, Kern Sibbald, Jack Stuppin, and John Walker.
Mike Ford discussed his work on marketing and the questions that need answering before we go much farther. He has got two Victor 9000's on loan (one from Sirius) for work on QBASIC and MicroCad, and has scored an MSDOS with assembler and linker. Also Pascal, for which we need another 128K memory. We have given a demo for Hal Elgie, a consultant for Sirius who was highly impressed, especially with Autodesk.
Mike's Victor dealership seems to have opened some doors. He could probably get a dealership for other machines if it would be useful.
There was considerable discussion of the terms on which we want to sell the programs. Our main options in dealing with Victor, and probably anyone else, are these:
(Many numbers were bandied about in the discussion. They are not in these minutes, because they would give a false air of precision and because widely distributed pieces of paper tend to pass before unauthorized eyes in spite of all precautions. Call us to talk about numbers if you like.)
There was general agreement with John Walker's opinion that a source buyout might be all right for a limited product like QBASIC-86, but not for MicroCad. The potential market for MicroCad is unexplored; it could be enormous, and no one would pay us enough to compensate for it. Victor could sell it under approach (2), putting their name on it if they want, but our name should at least appear on the disc and in the manual.
There was serious discussion of the right list price for MicroCad.
The consensus was that the present price on the M9900![]() is probably too low.
is probably too low.
QBASIC-86 would also be best sold on a royalty basis, though a buyout is conceivable. It should be easy to sell on the basis that it's a markedly superior language to CB-80, provided that we get it done well before Digital Research is ready.
Window is a product that would be a natural for Digital Research, which offers no usable editor for programmers; but we haven't managed to make a useful contact. Kern expressed concern that we shouldn't let it get completely out of our hands, because it's much better than anything else on the market. John pointed out the difficulty of trying to sell it ourselves, competing directly with VEDIT, which is becoming entrenched and has a large advertising budget.
We need to approach Corvus, Fortune, and anyone else who has a 68000; we should be able to get development machines from them. Also, the NSC 16032 is now approaching reality, and its speed makes it very attractive for MicroCad.
John Walker presented a financial report. Proceeds of the sale of stock and options were $59,030. Expenditures have been as follows:
IBM PC with printer, memory expansion, etc. 6,317 Sierra Z-80 boards (CP/M for M9900 users) 1,804 Stationery, copying, etc. 324 Supplies 337 Printing for Computer Faire 820 Legal fees 3,949
Income: $115 interest from Capital Preservation Fund.
We currently have $45,592 in liquid assets, almost entirely in Capital Preservation Fund. (Yes, Virginia, there is a round-off error in the totals.)
Each of the people present reported on what he has been doing:
Everyone was also asked to submit by Wednesday a list of tasks that he'll be working on over the next month or two, on a fairly detailed level. Submission can be either to John Walker or to the project managers concerned, who will forward the lists.
Dan Drake has been playing with a CPM program called MILESTONE, which runs under CP/M. There are now charts for the four main projects: Autodesk, MicroCad, QBASIC, and Window. Copies were handed out to everyone at the meeting; people who weren't there should request any that they want to see, so that we don't waste airmail postage on many charts that no one wants.
The time estimates in these charts are not in any sense imposed deadlines; they started as moderately optimistic guesses, intended to avoid the most obvious pitfalls in the critical paths. Anyone who finds himself on an unreasonable schedule can submit better estimates for the tasks that he's involved in. Many of the guesses were corrected at the meeting.
Any project leaders who don't see the CPM charts as a waste of time will probably want to maintain their own. We can get copies of MILESTONE for anyone who has CP/M (80) capability. It's worth seeing MILESTONE run just to see a really well done menu-driven program.
We now have letterheads and envelopes. Business cards for everyone will be available soon, probably with the default company title of Product Development Manager.
Dave Kalish has found a publisher who takes formatted ASCII text by phone and does typesetting and printing. We need to meet with him on technical details and prices. John Walker has a list of several publishers who accept some sort of floppy disc input (compiled from much-appreciated information from Richard Handyside and Peter Goldmann).
There was a discussion of the process of bringing new people into the company. The consensus was that anyone brought in on the same basis as the founders would require unanimous consent in some form. Assuming that the proposal had already been discussed, a final decision would not have to wait for a monthly meeting: management could poll everyone (possibly through the conference system on MJK) and proceed within a couple of days if there were no negative votes.
For future meetings, as for this one, the corporate secretary will prepare an agenda and attempt to protect the meeting from creeping formlessness. If there's something that needs to be on the agenda, please send a message to Dan Drake or John Walker a couple of days in advance, preferably on MJK.
The agenda will include progress reports of the same sort as were given at this meeting. Reports should be well under five minutes long; anything needing more discussion will be taken up later in the meeting. With these and the written list of tasks we'll be able to keep track of what's getting done and what's slipping.
The task lists and time commitments will be published regularly.
Here is the algorithm and schedule for monthly meetings:![]()
The schedule for the rest of the year, therefore (excluding the Annual Meeting) is as follows:
Sunday, August 1
Saturday, August 28
Sunday, October 3
Saturday, November 6
Sunday, December 5
I also included the original notes describing Auto Book in the Information Letter 7. Maybe someday we'll finish that product.
Auto Book is an idea for an automated document retrieval and examination system. What exists today is a prototype intended to play around with the concepts and try out bright ideas without a lot of effort. It is implemented in QBASIC on the M9900, and no effort has been expended to make it transportable. I'd rather have the convenience of trying out ideas readily than always trying to maintain compatibility.
Now that everybody has a computer, everybody will naturally write, edit, and print documents on the computer. As a result, more and more documents accumulate in machine readable form. Little has been done toward letting users read documents once they are written. If we have a computer between us and the document, we should be able to take more advantage of it than just having it print a hard copy that we later read.
Why shouldn't we be able to:
The idea I'm exploring is “Computer Assisted Reading”. It's a field I've seen little done with, and it's a far more universal need than even, say, VisiCalc. I'm calling the program “Auto Book” because it implements an automatic intelligent book. It also might be called the “Reader's Workbench”.
To get started, you should edit the file “ADI.CFG” on the Auto Book disc and change the “TERM” statement to specify your terminal type. The terminal type specified must be one listed in a “*” line in the file “WINDOW.TRM” on the disc. This is exactly like the CP/M Window configuration, and you may use the notes for that product to aid in configuring new terminals.
Put the Auto Book disc in Drive 1. Call the read utility with the command:
READ
When you are asked for a document name, answer:
USC
If you're about to ask me about the plus signs, it's because the terminal definition defaults to plus signs for “flagged” lines. They're reverse video on my terminal. If you have a special display mode, make the entries in WINDOW.TRM to use it on your terminal.
You will see a menu of commands. READ works in two major ways, by locating sections of a document by content, and by working with marks in the document set by the user while viewing it (just like attaching paper clips to pages, inserting bookmarks, or dog-earing pages). There is a list of all “referenced” sections known to READ at any time. Keep these ideas in mind as you read the explanations of the commands (it is a good idea to play around with the program as you read these sections).
You're asked for a word. All sections in which that word appears are added to the list of referenced sections. (That is, in the logical sense, they are OR'ed.)
You're asked for a word. All sections in which that word appears, and which have been previously marked as being referenced are marked as referenced. Other previously marked references are cleared.
You're asked for a word. All sections in which that word appears are removed from the reference list (if present).
All references are cleared from the reference list.
The titles of all sections referenced are listed. If more than a screen full of titles are referenced, the user can type “M” to see the next screen-load. “C” returns to the command menu.
The text from the document is displayed for referenced sections, starting with the first referenced. If the text is more than a screen full, typing “M” will show the next screen-load. Typing “N” shows the next reference, if any. Typing “C” gets back to the command menu. “+” advances to the next section in the document (referenced or not), and “−” backs up to the previous section. “S” sets a mark on the section, and “U” unsets (i.e., clears) the mark.
All section titles are displayed. “M” gets the next screen full, and “C” gets back to the command menu.
All sections which have been marked by the user (with the “S” key while viewing the text) are added to the list of referenced sections. To view just the marked sections, clear the reference list, then select marked sections.
The user is asked for a new document name, and viewing of that document is begun.
When viewing a screen other than the main command menu, pressing any illegal key (“?” is always illegal), will replace the display at the top of the screen with a list of the meaning of all the currently valid response keys. Entering a proper response will turn the help display back off.
Auto Book consists of a document processor which reads the formatted text generated by a word processing program. The preprocessor scans the document, and based either on information encoded in the document, or by user-selected heuristic rules, identifies logical sections of the document and assigns them names. It prepares a rapid-access file of the document text, and creates a file containing encoded references to words in the document with pointers to the sections of text in which each word appears. The preprocessor may also perform compression of the text, and encode it against access by programs other than the Auto Book retrieval program. Neither of these functions are currently implemented.
The preprocessor contains an algorithm called the “rooter” which extracts the root of words with prefixes and suffixes. This algorithm must be carefully defined, and will vary for each natural language supported. References are stored by the root of the words, so that asking for references to “test” will find references to “test”, “tested”, “tests”, “tester”, “retest”, etc. This is not currently implemented.
Once a document has been “compiled” by the preprocessor, it may be read with the “READ” utility.
The preprocessor is invoked by calling the SCAN program. It presents a menu allowing only the options of preprocessing a document or exiting. Before calling SCAN, you should have put the WORD formatted output of the document into a file with a .TXT type. You should also create a file with the same name and a .RAT type with size about one sector per line of text in the .TXT file. You should also create a .REF file. There's no easy way to estimate the .REF file size, so make a huge file initially. SCAN will tell you how much it used after it's done. You should have a TEMP1$ file on Drive 1 (MDEX) before calling SCAN.
Once you tell SCAN you want to process a document, all you have to do is enter the “root name” (less the .TXT) of the document, and SCAN will do the rest.
SCAN knows about various commands embedded in the document. These commands will be removed from the files created by SCAN. All commands are flagged with a plus sign (+) in column 1. Note that these commands are entered as text with WORD, and that care must be taken to insure that WORD will not format them into the middle of another line. See the file “USC.WRD” for an example of how the SCAN commands can be inserted in a document.
The following commands are recognised by SCAN.
+TITLE text
The text is saved as the document title. The title is always displayed while the document is being read.
+COPYRIGHT text
The text, which should be of the form “1980 Mud Slingers International” will be displayed as a copyright notice when the document is being viewed. This may, in the future, be used to control reproduction of an encrypted document.
+number text
If a single digit number from 1 to 9 follows the plus sign, this specifies a section break in the document. Up to 9 levels of sections are allowed. The title for each section is the concatenation of all sections with numbers less than or equal to the last section number which appeared.
Important: If no +number item is used, SCAN will break the document into paragraphs separated by blank spaces. Each will be assigned a paragraph number. This allows unencoded documents to be processed reasonably.
To see the process involved in running SCAN at work, look at the original document text “USC.WRD” on the documents disc. This text is processed by WORD to form the text file “USC.TXT”. When SCAN is run over this document, the files “USC.RAT” and “USC.REF” are generated. These files are then accessed by READ.
The list of commands in READ and the whole idea of the command menu is distasteful. I think maybe a simple command language or some form of directed prompting would be more in order. The current set of commands evolved largely out of a desire to test the various sections of the program in an orthogonal manner. I'm sure a more elegant set of ideas should underlie the commands.
You should be able to do a lot more with marks in the text. They should be saved when you sign off or view another document, and you should be able to clear them, easily display them, automatically set marks for all referenced sections, etc., etc.
There should be a +ALIAS command in SCAN. Sometimes you want a section to be selected when a word not used in it is referenced. For example, the “necessary and proper” clause in the U.S. Constitution might have a +ALIAS ELASTIC before it, as it is often known as the “elastic clause”. It could be found by its common name, even if the user didn't know what it said.
There's another aspect to aliases. You might want to have an alternate word or words indexed every time a given word is used. This would let relevant sections be retrieved regardless of which synonym were used. For example: +ALIAS BONNEY=BILLY THE KID . would index “Billy the Kid” every time the desperado's real name were used in the text.
Inter-document references: A complete system should let you file all your documents and move freely between them. SCAN could implement this with a +KEYWORDS statement listing keywords in the document for the global dictionary. One could start at the global level and get a list of all documents with selected keywords, then move on to read them. References between documents would be handled by a +SEE statement. One might, for example, in a manual about the text editor, insert the statement:
+SEE SYSTEM REBOOT,LOAD,CREATE,FILE,DELETE,…where the user would be given a reference to the manual “SYSTEM” when one of the listed words were asked for.
SCAN should also have a command called +EXPLAINS. Before a section, one should be able to insert a statement like:
+EXPLAINS CHANGE,ALTER
and have it flagged as the section which explains those terms. Then the user reading the document could ask for the explanation of a term (rather than just the references) and get the section providing the most basic definition of the term.
When you're reading a real document, you can make marginal notes. READ should allow this too. The master copy of the document remains unchanged, but a user can “annotate” any section by typing in text which gets saved in a special notes file belonging to that user. When the section of the document is viewed, the user can see that he's made notes, review the notes, and edit them as desired.
The format SCAN stores the text in is wasteful of space, and results in each document being stored as two files (.RAT and .REF). This is because I was lazy. Fixing it wouldn't contribute anything to evaluation of the product idea. In a production system, one file should contain all information for a document, and the document text should be compressed using the “polygram compression” algorithm used in SPELL. Also, a simple encryption should be done to protect documents from being ripped off by the honest and naive. Whether the user is allowed to make a hard copy or store decoded text in a file would be controlled by a flag on the copyright statement in the document. Compression is very important because the value of this system depends on how many documents you can keep on-line.
There should be a way in READ to locate text by section title as well as by word references. I'd suggest a command which lets you specify words from the section title. It scans the section titles and looks for a section title containing all the words you used in your specification (regardless of order). If more than 1 were selected, you could look at them and choose the right one.
More general facilities should be available for moving around in the text when looking at text with READ. You should be able to:
These facilities are why I think that a “command line” at the end might be better then the menu/view mode presently installed.
Also, should we encode the hierarchical structure of the document? We know the levels based on the encoding given to SCAN. We might want to say, “Go to the next chapter”, or such.
One of the most complicated design tasks is the “rooter”. I think
the guts of the
![]() hyphenation algorithm are a good start. We
want to index the original word, then add the derivative forms,
flagged as such. Then we can retrieve based on the exact form, or
any derivative form.
hyphenation algorithm are a good start. We
want to index the original word, then add the derivative forms,
flagged as such. Then we can retrieve based on the exact form, or
any derivative form.
I don't expect most people to make as much effort encoding a document as we might make in indexing manuals for distribution with this thing. Thus, SCAN should be far more intelligent in breaking up documents into sections based on heuristic rules. We'll need to learn what information there may be in a WordStar file, for example, which would help in this task. The utopian idea is that once any document is written (letters, etc.), in an office, the original text is archived, and the formatted text is run through SCAN and saved on-line. Anybody who refers to it does so with READ. This makes references more productive, saves disc space, aids in building a master document library, and allows readers to make annotations without either changing the original or copying it.
Don't be upset by how slowly SCAN runs. I used a stupid merge algorithm in sorting word references. It should be able to be speeded up to run faster than WORD. For evaluation, it serves.
Yes, READ is awfully fast, isn't it? The sneaky way it looks up indexed words remains fast even with very large documents.
You can also use READ to aid in access to paper documents. To do this, just make WORD crank out a:
+1 Page number
item in the HEADING macro. Then all sections will be flagged with the page number.
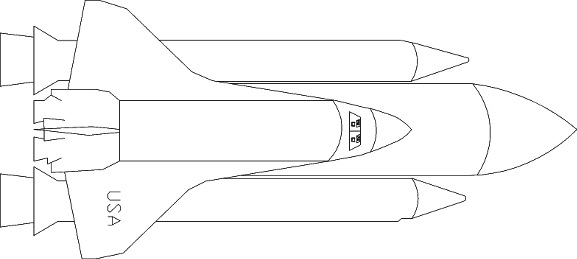
This drawing was, to my knowledge, the first actual drawing ever done with AutoCAD (other than scribbles made while testing the program). I initially drew it on AutoCAD-80 before text was even working, then added detail as parts of the package were implemented. The drawing was made by taping the cover of a Time magazine issue from late 1981 featuring the shuttle to a HI-Pad digitiser and tracing the drawing. The picture in the magazine wasn't precisely a face-on view; that's why the drawing is slightly asymmetrical. This drawing was also the first BLOCK ever used with the INSERT command, and the first drawing ever to be plotted with AutoCAD (on a Houston Instrument DMP-8 plotter). The CHANGE command was initially implemented to help clean up the raw digitised coordinates in this drawing.
|
|